| Hierarchical Temporal Transformer for 3D Hand Pose Estimation and Action Recognition from Egocentric RGB Videos | |||
| Yilin Wen1, Hao Pan2, Lei Yang3,1, Jia Pan1,Taku Komura1, Wenping Wang4 | |||
|
1The University of Hong Kong,2Microsoft Research Asia, 3Centre for Garment Production Limited, Hong Kong, 4Texas A&M University |
|||
|
CVPR 2023 (Extended Abstract at HBHA Workshop, ECCV 2022) |
|||
| Abstract | |||
| Understanding dynamic hand motions and actions from egocentric RGB videos is a fundamental yet challenging task due to self-occlusion and ambiguity. To address occlusion and ambiguity, we develop a transformer-based framework to exploit temporal information for robust estimation. Noticing the different temporal granularity of and the semantic correlation between hand pose estimation and action recognition, we build a network hierarchy with two cascaded transformer encoders, where the first one exploits the short-term temporal cue for hand pose estimation, and the latter aggregates per-frame pose and object information over a longer time span to recognize the action. Our approach achieves competitive results on two first-person hand action benchmarks, namely FPHA and H2O. Extensive ablation studies verify our design choices. | |||
| Algorithm overview | |||
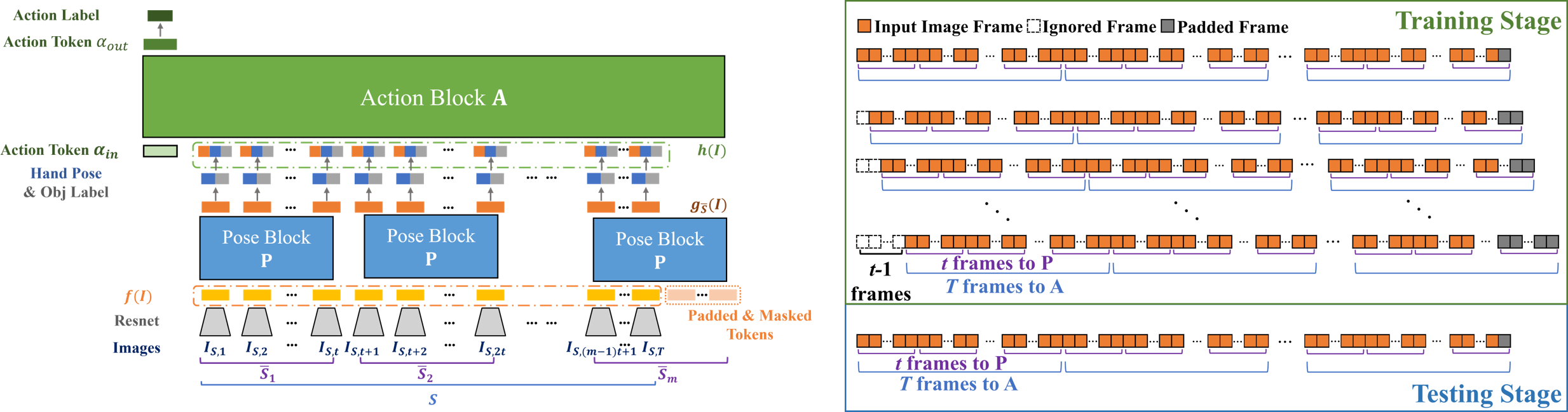 |
|||
| Left: Overview of our framework. Given input video S, we first feed each image to a ResNet feature extractor, and then leverage short-term temporal cue via P applied to shifted windowed frames, to estimate per-frame 3D hand pose and object label. We finally aggregate the long-term temporal cue with A, to predict the performed action label for S from the hand motion and manipulated object label. We supervise the learning with GT labels. | |||
| Right: Segmentation strategy for dividing a long video into inputs of our HTT. In the testing stage, we start from the first frame, while in the training stage, we offset the starting frame within t frames to augment the training data diversity. | |||
| Results | |||
 |
|||
| Qualitative comparison of different t for 3D hand pose estimation on H2O dataset. For t=16,128, the attention weights in the final layer of P is visualized. Our t=16 shows enhanced robustness under invisible joints compared with the image-based baseline of t=1, while avoids over-attending to distant frames and ensures sharp local motion compared with a long-term t=128. | |||
 |
|||
| Visualization for weights of attention in the final layer of A, from the action token to the frames. Presented is a video of take out espresso from H2O dataset, whose down-sampled image sequence is shown in the top row. The last few frames are the key for recognizing the action; in response our network pays most attention to these frames. | |||
|
|||
| ©Y. Wen. Last update: Aug, 2023. |
